
카레제육 블로그
AWS EKS 인스턴스 타입에 따른 성능 비교 본문

이번 게시글은 지난번 작성한 쿠버네티스에서 리소스와 성능을 비교했던 글의 후속작이라고 볼 수 있습니다. 지난 게시글은 아래와 같습니다.
2022.05.02 - [IT 이야기/kubernetes, docker] - 쿠버네티스 부하테스트로 리소스와 성능의 상관 관계를 알아보자
지난번 테스트는 노드 자체의 스펙은 변경하지 않고 쿠버네티스의 Request, Limit만 변경하며 성능을 제한하고 테스트를 진행했었다. 하지만 테스트를 하면서도 쿠버네티스의 리소스 제한옵션이 정말 완벽하게 통제할 수 있는가와 인그레스를 사용했을때 nginx 컨트롤러의 부하때문에 혹시 대역폭에 영향이 있지 않았을까? 하는 점 등 여러 의문이 남아있는 상태로 진행하여 찜찜함이 남아있었다.
의문을 남긴채로 끝낼 수 없어 이번에는 조금 수고스럽더라도 직접 노드의 스펙자체를 바꿔가며 테스트틑 진행했고, 인그레스 등 다른 기능을 모두 덜어내고 웹 서버만 올려서 진행했다. (때문에 모니터링이 없다! ㅜㅜ)
시스템 자원에 따라 성능은 어떻게 달라질까?
지난번 테스트에서 쿠버네티스의 리소스 관리 기능을 사용한 테스트에서 리소스는 성능에 어느 정도 정비례한 모습을 보이다가 어느 순간부터 정비례는 깨지고 단순히 리소스가 많아졌으니 성능도 좋아진다는 정도의 예상할 수 있는 결과만을 보여주었다. 이번 테스트에서는 시스템 자체의 자원을 바꿔주며 테스트를 진행하여 정비례하는 모습을 기대해본다.
시스템 자체의 스펙을 바꿔주기 위해서 AWS의 EKS 상에서 노드를 바꿔가며 테스트를 진행하기로 하였다. AWS는 다양한 인스턴스 타입을 제공하며 간편하게 시스템을 마이그레이션 할 수 있도록 서비스를 제공한다.
인스턴스 타입에따라 vCPU와 Memory가 다르다. 더 나아가 간과할 수 있는 부분이 네트워크 대역폭, IOPS 등 고려할 사항이 상당히 있다. (AWS 인스턴스 유형 https://aws.amazon.com/ko/ec2/instance-types/)
이번 테스트에서는 vCPU와 Memory만을 두고 비교하고 싶어서 동일한 유형에서 스펙만 변경하며 진행하였다. 내용의 순서는 아래 표와 같다.
| 모델 | vCPU | 메모리(GiB) | 인스턴스 스토리지(GB) | 네트워크 대역폭(Gbps) | EBS 대역폭(Mbps) |
| c5.xlarge | 4 | 8 | EBS 전용 | 최대 10 | 최대 4,750 |
| c5.2xlarge | 8 | 16 | EBS 전용 | 최대 10 | 최대 4,750 |
| c5.4xlarge | 16 | 32 | EBS 전용 | 최대 10 | 4,750 |
테스트 방법
지난번과 동일한 부하 발생 애플리케이션을 사용하였지만 이번에는 단순히 요청서버와 응답서버 두 개의 서버만을 이용한다. 리소스를 변경할 때마다 인스턴스 타입을 변경하기 위해서 노드를 내리고 새로운 노드를 올려 파드를 할당하였다.
특히 이번에는 실제 데이터가 몰리는 상황을 연출하기 위해서 각 테스트 마다 600s(10분) 동안 요청 바디사이즈 100Kb, 응답 바디사이즈 100Kb 그리고 응답서버에서 딜레이되는 지연시간 1000ms(1초)를 설정하였다. 이정도 부하라면 실제 상황에서도 충분한 대용량 데이터 부하라고 생각하여 설정하게 되었다.
1. 요청서버
요청 서버는 go로 작성되었다. 부하 발생 요청을 받기위해 ECHO 프레임워크를 사용하였으며 사용자로부터 목적지url, TPS, 테스트시간, 지연시간, 요청 바디사이즈, 응답 바디사이즈 설정값을 받아 테스트를 시작한다. 요청 서버의 인스턴스 타입은 c5.4xlarge를 사용하여 16vCPU, 32GiB 메모리를 가졌다.
2. 응답서버
응답 서버 또한 go로 작성되었으며 동일하게 ECHO 프레임워크를 사용해 웹서버를 구축하였다. 요청받은 내용의 지연 시간 설정을 읽어 강제적으로 응답을 바로 보내지 않고 해당 시간만큼 지연시킨다. 응답 서버의 인스턴스 타입을 테스트마다 변경하여 컴퓨팅 자원에 변화를 주며 진행하였다.
테스트 결과를 읽는 방법
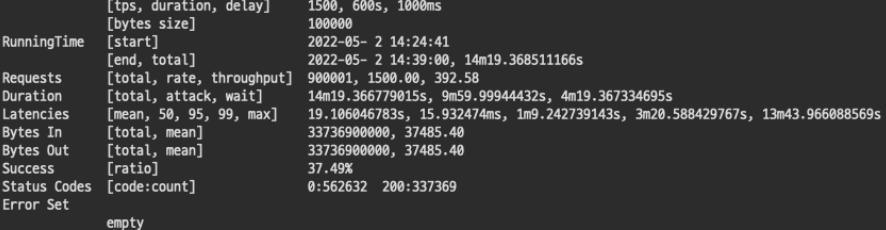
이번 테스트에서는 요청시에 지연, 요청바디 사이즈, 응답바디 사이즈가 추가되었기 때문에 결과에서 지난번보다 주의깊게 읽어야 할 내용이 많다. (결과만 알고싶다면 성공률만 봐도 무방하다.)
tps: Transaction Per Second(초당 트랜잭션의 수)
duration(s): 총 요청 시간
delay(ms): 지연시간
bytes size: 요청 바디 사이즈
Requests total: 총 요청 수 (tps*duration)
Bytes In: 응답에서 들어온 바디 바이트
Bytes Out: 요청으로 나간 바디 바이트
Success: 성공률

노드에 다른 파드를 띄우지 않았기 때문에 EKS k8s에서 기본적으로 지원해주는 메트릭서버에 요청해서 pod리소스 사용하여 사용량을 모니터링 한다.
테스트 내용
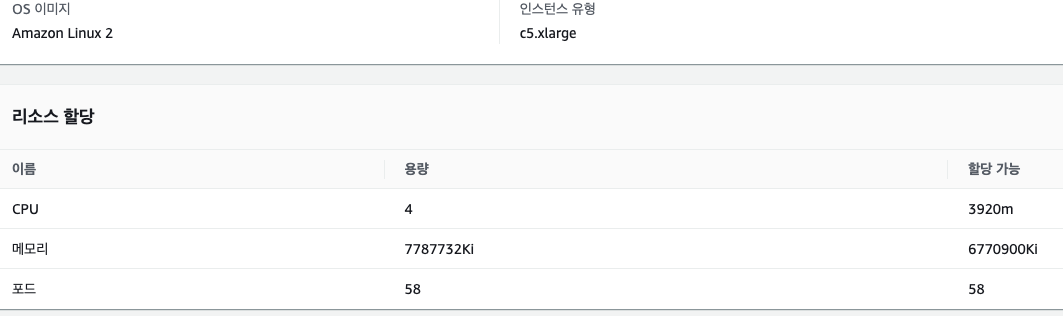
1#. c5.xlarge 4vCPU 8GiB 메모리
1-1. TPS 800

테스트 중반쯤 kubectl top을 찍어봤을때 내용이다. 요청 서버는 1249m/826Mi 를 사용중이고 응답 서버는 3588m/711Mi 를 사용중이다.
top 값이 안정적으로 보인만큼 결과도 안정적으로 성공한 것을 볼 수 있었다. TPS 값을 높이며 본격적으로 진행해보자
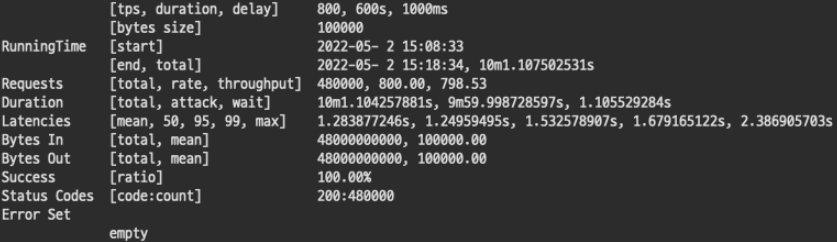
1-2. TPS 1000

모니터링 값 모두 인스턴스 리소스 크기 내 값을 보이며 안정적으로 보인다.

안정적으로 보이는 리소스 모니터링 값과 다르게 결과는 처참하게 실패했다. 생각과 다르게 4코어 8기가로는 1000 TPS 조차 버티지 못했다. 사실 당연히 성공할거라 생각하여 TPS 800보다 먼저 시행했던 값이다.
2#. c5.2xlarge 8vCPU 16GiB 메모리
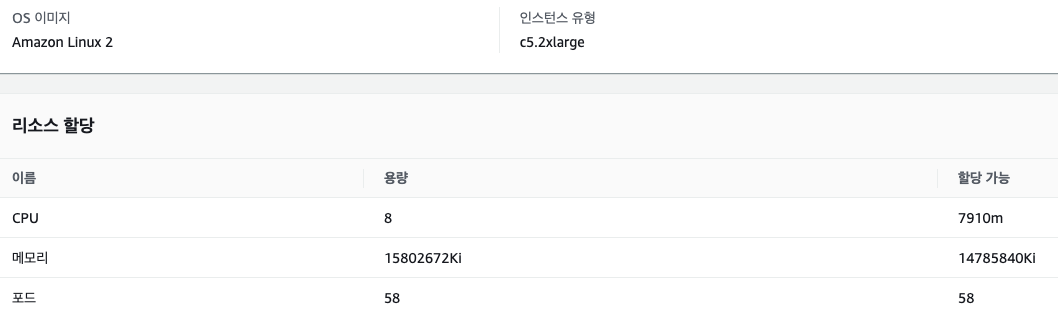
2-1. TPS 1500

확실히 1500 TPS를 처리하는데 많은 리소스가 사용되고 있다. 요청 서버보다 응답 서버가 힘들어하는 모습을 보인다. 바로 응답을 보내지못하고 지연을 하기때문에 응답 서버에 많은 부하가 걸리는것으로 보인다.
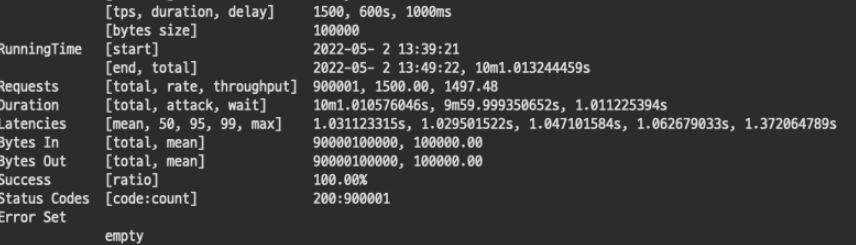
응답 서버가 가진 리소스를 거의 사용하는것처럼 보여 실패를 예상했는데 훌륭하게 성공해냈다.
2-2. TPS 2000

뭔가 이상하다. 1500 TPS 와 사용량의 차이가 거의 없다.
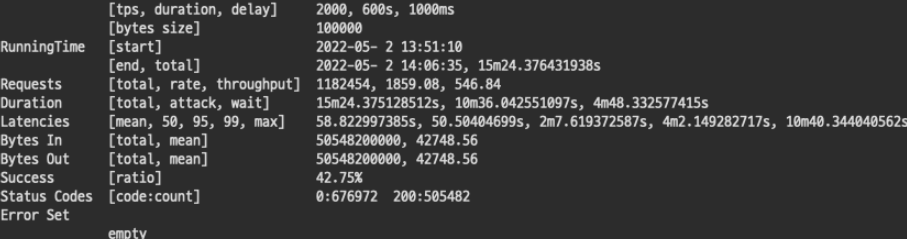
결과는 역시나 처참하게 실패했다. 요청을 처리하는데 리소스 사용량이 1500과 비슷한 모습을 보이는것으로 추측하면 최대힘을 내는 수치가 아니었을까 싶다.
3#. c5.4xlarge 16vCPU 32 GiB 메모리
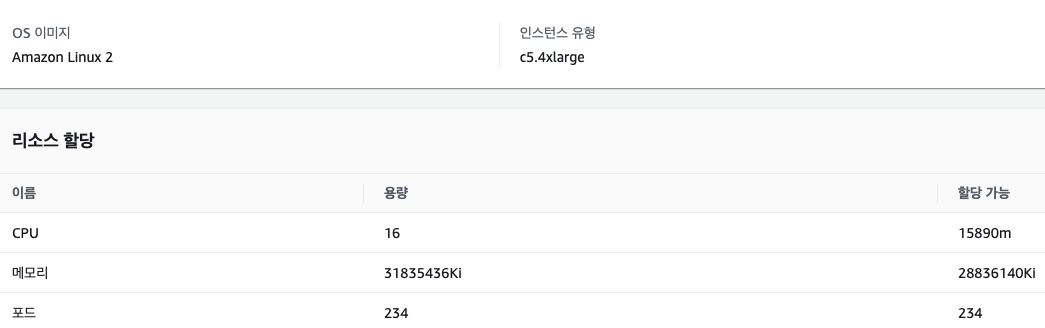
3-1. 2000 TPS

지난 테스트 값들과 비교해본다면 안정적인 리소스 사용량이라고 볼 수 있다.
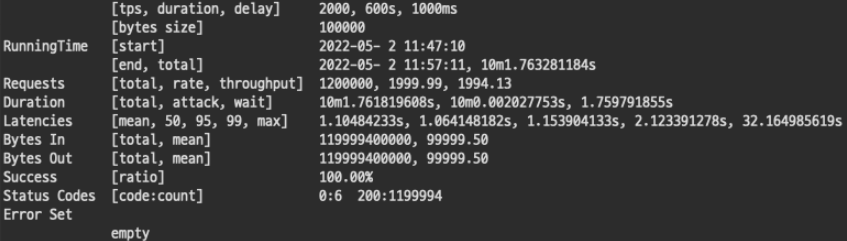
TPS 2000으로 무려 10분동안 총 1199994개의 요청을 성공했다. (6개는 뭐지?) 하지만, 리소스 사용량을 봤을때 한계라고 볼 수 있다.
3-2. 3000 TPS

3000 TPS를 시도했을때, 리소스의 값이 이상했다. 요청 서버의 사용량이 높게 튀고 있어 실패라고 예상되었고 결과는 역시나... 계속 응답을 기다렸지만 영영 답이 오지 않았고 설정한 타임 아웃값에따라 요청이 종료되었다.

이상한 리소스 사용량을 보고 혹시나 pod가 내려갔나 싶어 확인했지만 재시작된 기록은 보이지 않았다. 단단히 문제가 있다! 그래서 요청시간을 10분의 1로 줄여 1분 테스트를 진행했더니 결과는 다음과 같았다.
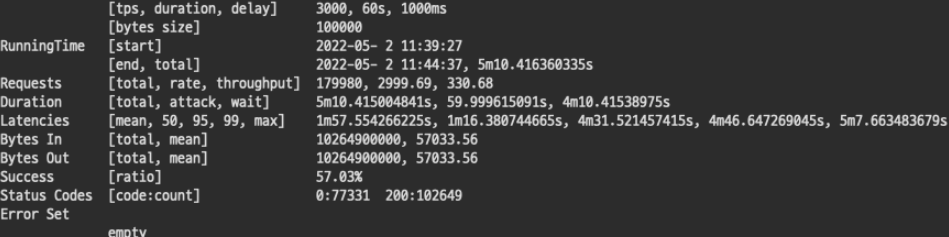
1분 진행한 테스트 조차 실패가 반으로 보이는데 10배는 얼마나 처리하기가 힘들었을까 문제가 생길만하다. 3000TPS는 요청 서버의 스펙만해도 부족한것으로 보인다.
결론
이번 테스트 또한 예상과 같이 리소스의 스펙에 정비례하여 성능이 향상하는 모습은 볼 수 없었다. 하지만 막연히 스펙이 높으면 성능 좋겠지. 정도의 추측에서 특정 스펙이면 어느 정도의 부하를 견딜 수 있다를 직접본것만해도 큰 수확이라고 생각한다.
마무리
지난번 테스트에 비해서 간결해진 내용으로 의구심이 해소가 되었다. 특히 결론에 적은 것과 같이 특정 부하에서 이 정도 스펙이 필요합니다. 라고 당당하게 말할 수 있는 근거를 가지게 되어 내심 뿌듯하다.
실제 서비스에서는 이렇게 단순한 구조가 아닌 여러 아키텍처를 가져가기 때문에 부하 처리를 위해서 이중화 삼중화 구조를 가진다고 알고 있다. 언젠가 부하 처리를 위한 아키텍처를 직접 구축하고 테스트 결괏값을 내고 싶다.

