
카레제육 블로그
쿠버네티스 부하테스트로 리소스와 성능의 상관 관계를 알아보자 본문

쿠버네티스는 파드에 대해 Request와 Limit 속성을 주어서 리소스를 관리할 수 있다. 그런데 이 속성이 성능에 얼마나 영향을 줄까 궁금해졌다.
(파드 및 컨테이너 리소스 관리에 대하여 https://kubernetes.io/ko/docs/concepts/configuration/manage-resources-containers/)
정말 리소스에 비례해서 처리성능은 향상될까?
먼저 리소스와 성능에 대해 고려하게 된 이유는 EKS를 사용하며 노드 그룹을 관리하는데 나중에 리소스가 부족할 때마다 마이그레이션 하는 작업에 있어 사이드이펙트에 대한 피로도 때문이었다. 최초에 리소스를 적절하게 설정하면(AWS 인스턴스 타입 잘 선정한다면) 어느 정도 커버할 수 있지 않았을까? 그래서 적절한게 어느정도인데?
적절한 인스턴스를 선택하기에 앞서 필요한것은 k8s의 리소스를 잘 관리하는 것이며 이에따라 사용 리소스를 예상하는것이었다. 때문에 k8s의 request와 limit을 이용한 부하테스트를 직접 진행해보기로 했다.
테스트 방법
테스트 방법은 간단하다. 부하를 발생하는 요청서버, 부하를 받아주는 응답서버, 그리고 리소스 변인이 되는 중간 라우터 역할을 해주는 게이트웨이 서버 3개 즉. 엔드포인트 3개를 사용한다.
부하테스트 환경
1. 요청서버와 응답서버
필요한 요청서버와 응답서버는 개인적으로 동시 처리 능력이 아주 좋다고 생각하고 실제로도 호평을 받고 있는 Go를 이용해 간단하게 구축하였고 앞으로 한개의 클러스터에 두개의 노드를 띄워서 각각 배포하였다. 인스턴스 타입은 c5.4xlarge 타입을 사용했는데 16core 32gb 메모리로 부하요청, 응답서버의 처리량 부족으로인한 테스트 실패를 만들지 않기 위해서 넉넉하게 잡았다. (c5.4xlarge *2 의 인스턴스)
부하 발생 방법은 go로 작성된 오픈소스 vegeta를 기반으로 테스트 환경에 맞게 수정하여 사용하였다.
https://github.com/tsenart/vegeta (드래곤볼의 전투력 측정기 그 베지타가 맞습니다.)
2. 테스트 대상 게이트웨이
실제 테스트 대상이 되는 위치로 새로운 클러스터와 노드를 띄워서 배포하였는데 이는 의도적으로 다른 네트워크를 타게 하여 트래픽이 안에서 도는 것을 막기 위해서였다.
(이 부분에대해서 지식이 부족하여 조언을 기다립니다. 같은 AWS망이라면 혹시 DNS 서버가 알아서 AWS 망안에서 도는지 다른 VPC를 사용하도록 하였는데 의도대로 외부망을 나가는지 확실하지 않네요)
게이트웨이 서버는 kong이라고 불리는 게이트웨이 오픈소스를 사용했다. kong 라우팅 서비스에 응답 서버의 주소를 지정하고 요청 서버에서 kong의 엔드포인트로 요청을 보내면 kong 게이트웨이는 설정에 따라 요청서버의 엔드포인트를 찾아서 전달해주는 방식으로 일반적인 게이트웨이 작동과 동일하다.
3. 공통조건과 고려하지 않는 부분
- 테스트에 관련된 모든 서버는 ingress-nginx를 통해 proxy되며 이는 각 서버와 다른 노드에서 동작하고있는 controller에 의존합니다.
- http 통신에 있어 rate-limiting이나 기타 정책은 적용하지 않았습니다. 각 트랜잭션을 구분할 수 있는 xid를 가진 post를 사용합니다.
테스트 결과를 읽는 방법
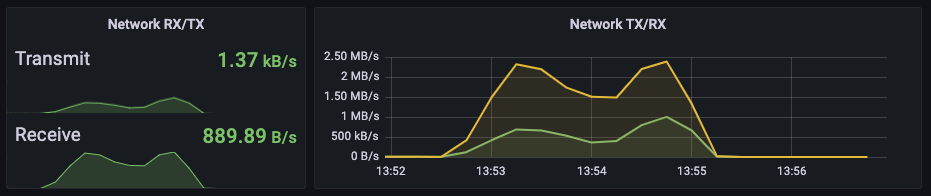
먼저, 게이트 웨이의 상태는 아래와 같은 방식의 그래프를 통해 확인할 수 있습니다.
그래프를 읽는 방법은 간단히 그래프가 예쁜 정규분포 그래프를 그린다면 부하의 처리에 따라 상승과 하강을 그려 따라 잘 처리된것입니다.
아래의 텍스트와 같이 요청서버로 돌아오는 응답을 바탕으로 결과를 판단할 수 있습니다.
이번 테스트에서 결과를 읽기 위해 필요한것은 아래와 같습니다.
tps: 초당 요청 수
duration: 요청 시간
start: 테스트 시작시간
end: 테스트 종료시간
total: 테스트 총 소요시간
success: 테스트 성공률
status codes: 응답 상태 코드
테스트 내용
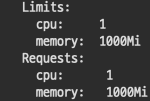
1000 core = 1.0vCPU , 1000 mem = 1g 를 의미합니다.
1#. 500 cpu, 500 Mi
1-1. TPS 1000 OK
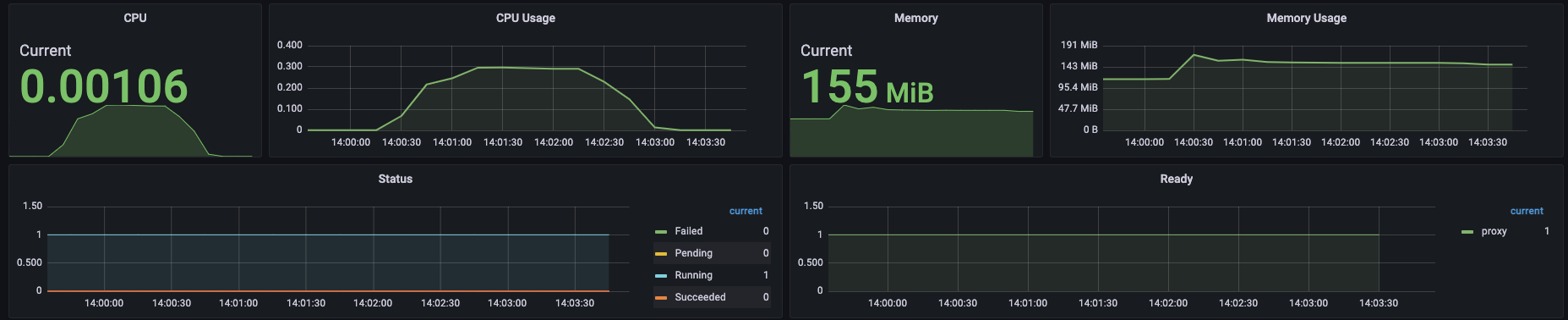
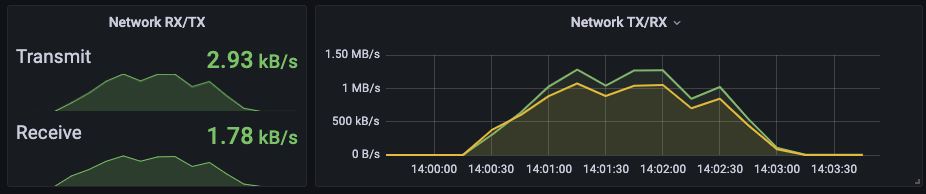
초당 1,000건의 HTTP 요청은 충분히 처리해준다. 각종 교육프로그램에서 개인 개발자가 웹서버 구동하는데 1g 1g면 충분하다고 하는 이유를 이제 알 것 같다.
1-2. TPS 2000 Fail
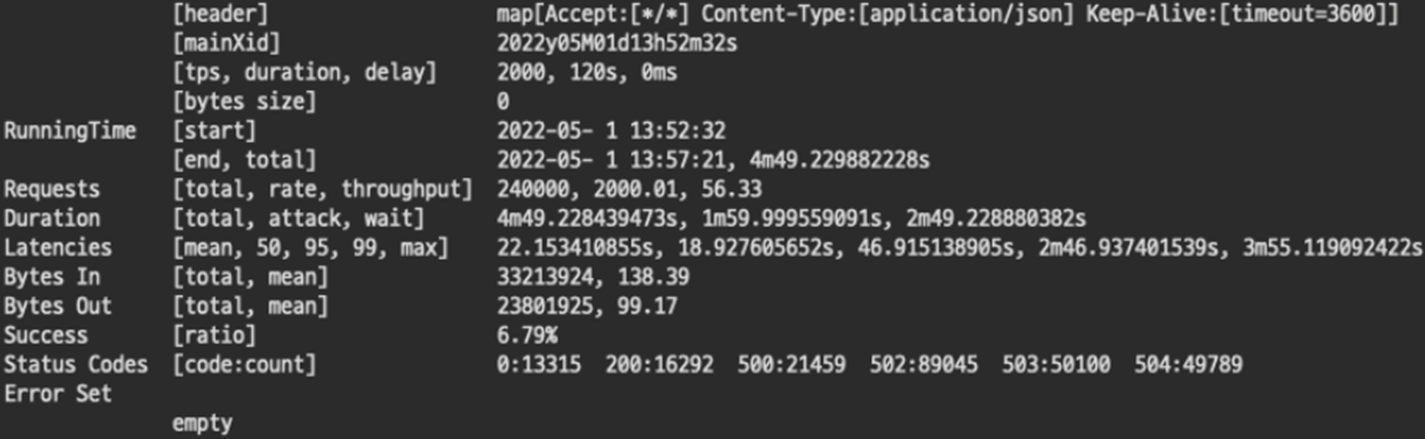
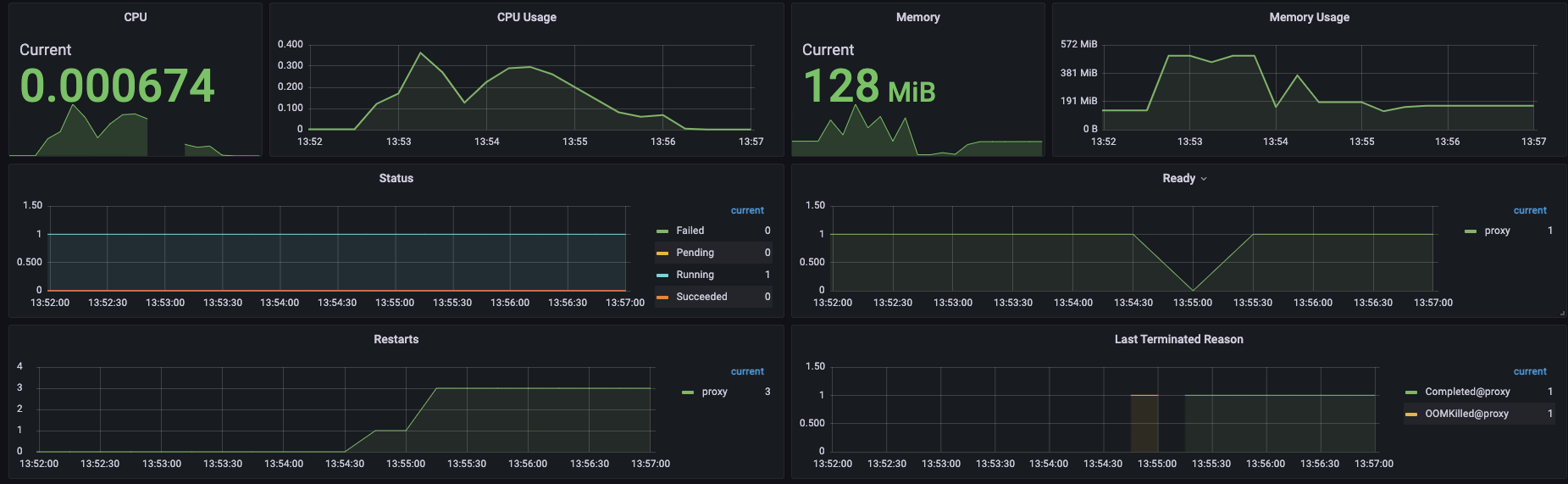
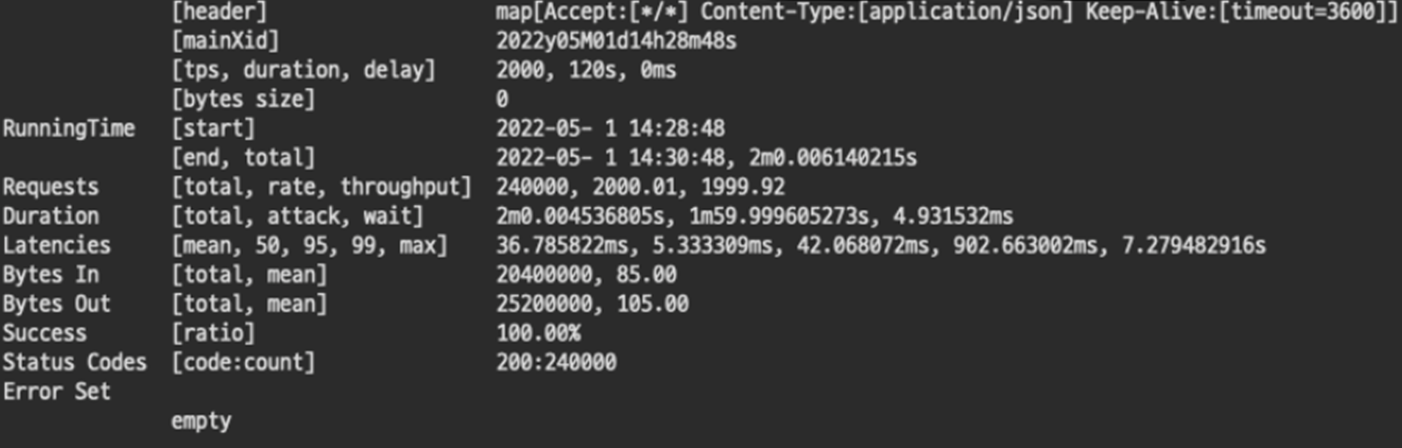
초당 2000개의 트랜잭션의 경우 성공률 6.79%로 실패하였다. Status Codes를 확인해보면 처참하다. 500으로는 역시 턱없이 부족하다.
2#. 1000 cpu, 1000 Mi
2-1. TPS 2000 OK
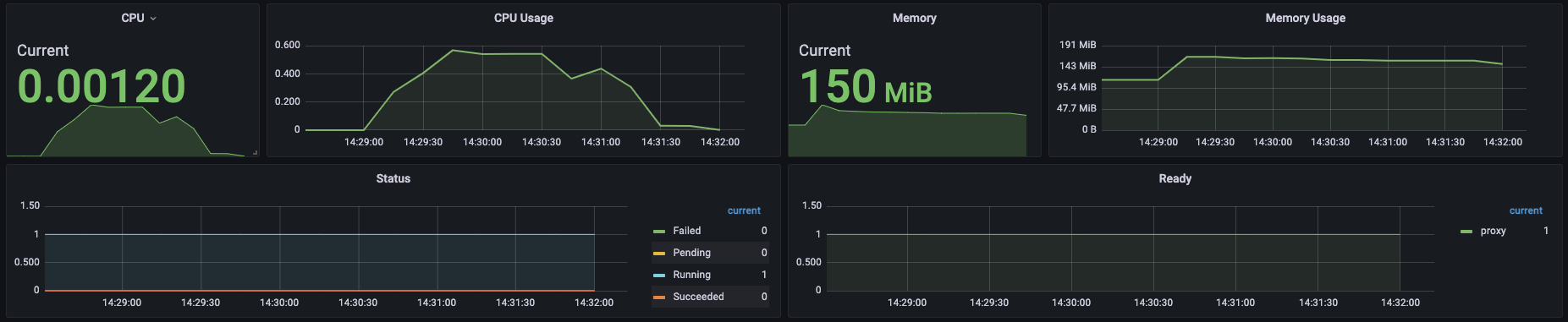
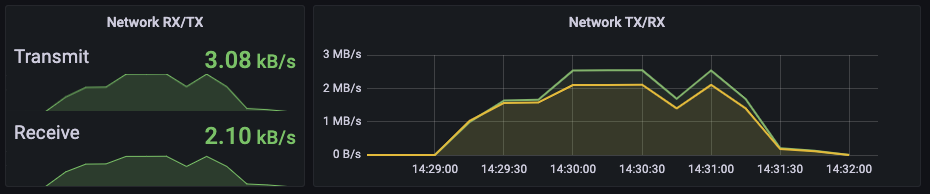
2-2. TPS 3000 Fail
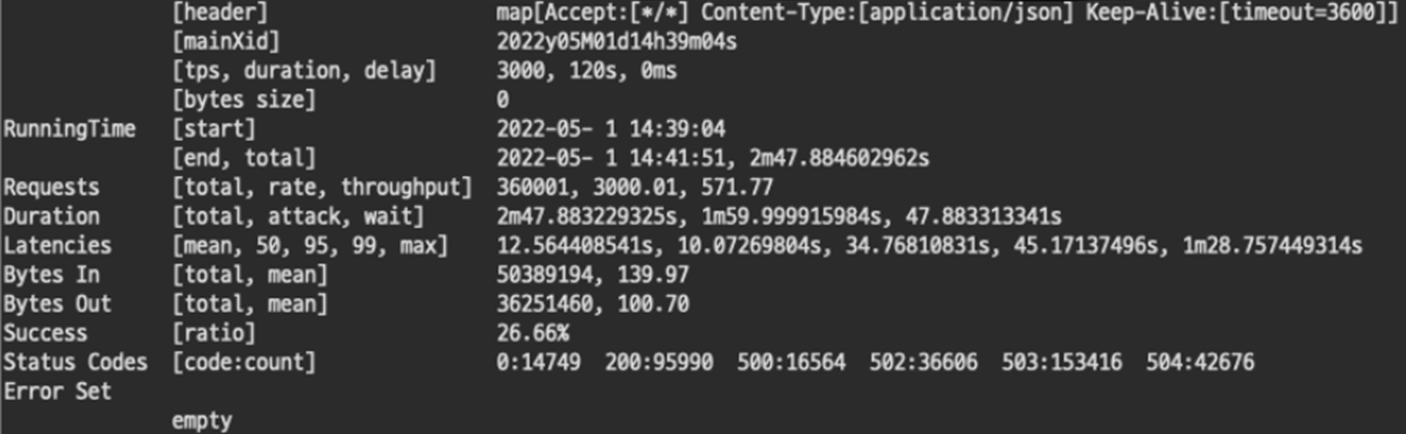
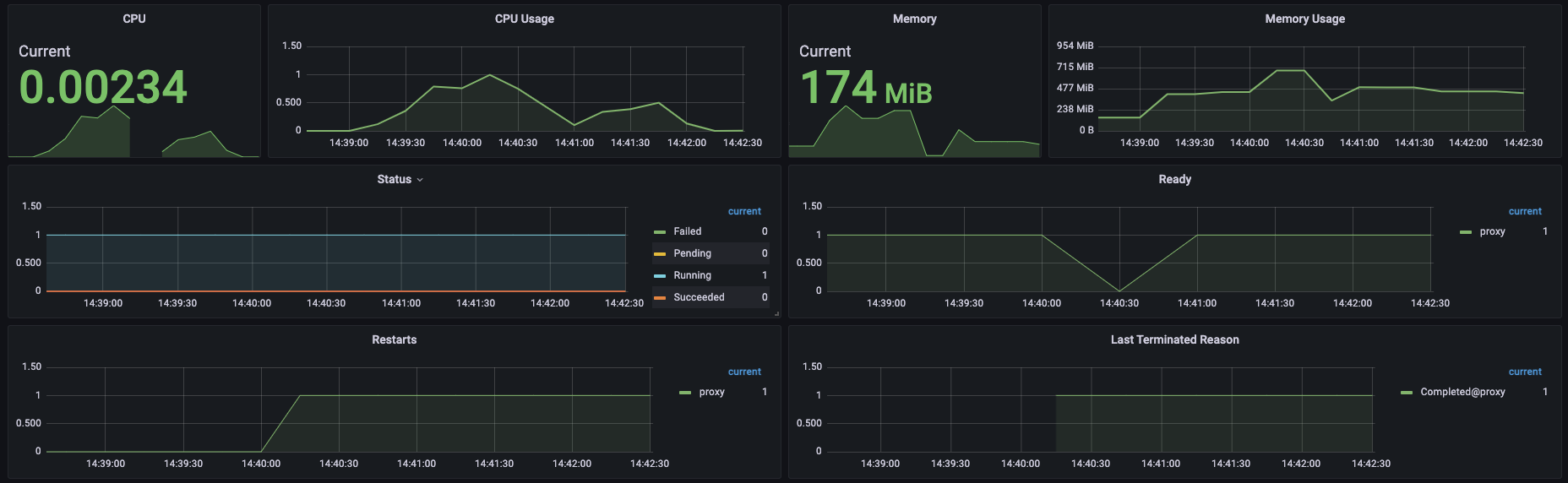
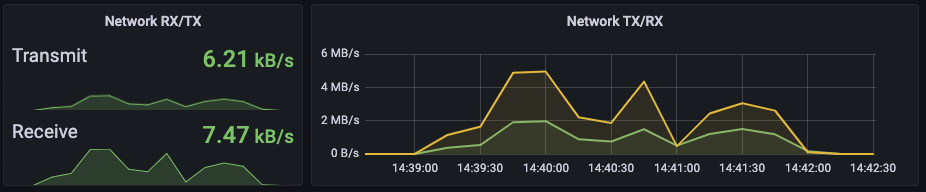
3#. 1500 cpu, 1500 Mi
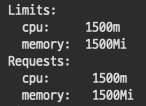
3-1. TPS 3000 Fail
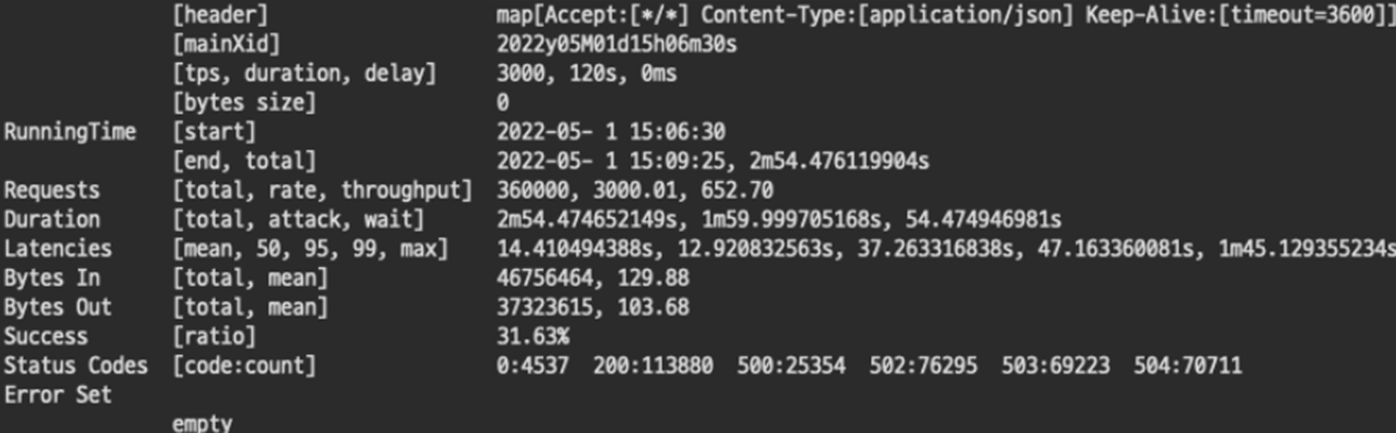
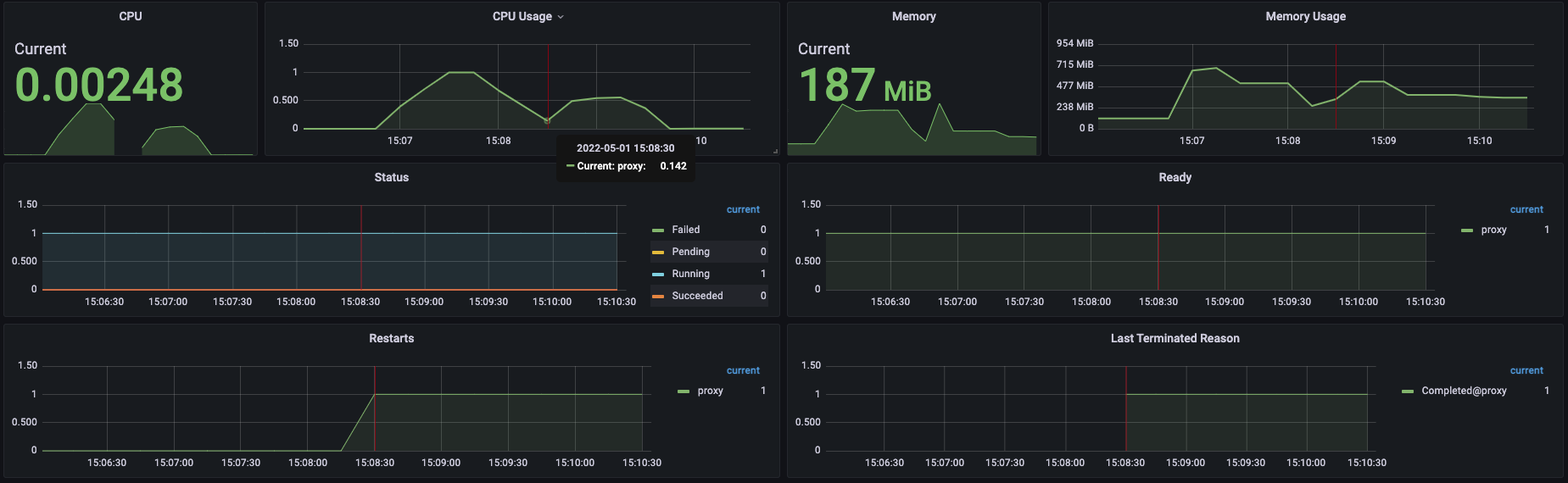
500과 1000을 비교해보면 마치 리소스가 올라감에 따라 정비례로 처리 성능도 올라가는것처럼 보였으나 1500에 와서는 다른 양상을 보이기 시작한다. 500보다 3배 높기때문에 TPS 3000을 처리할것이라 예상하였지만 불가능하였다. 그럼 살짝 낮춘 TPS 2500를 시도해보자.
3-2. TPS 2500 Fail
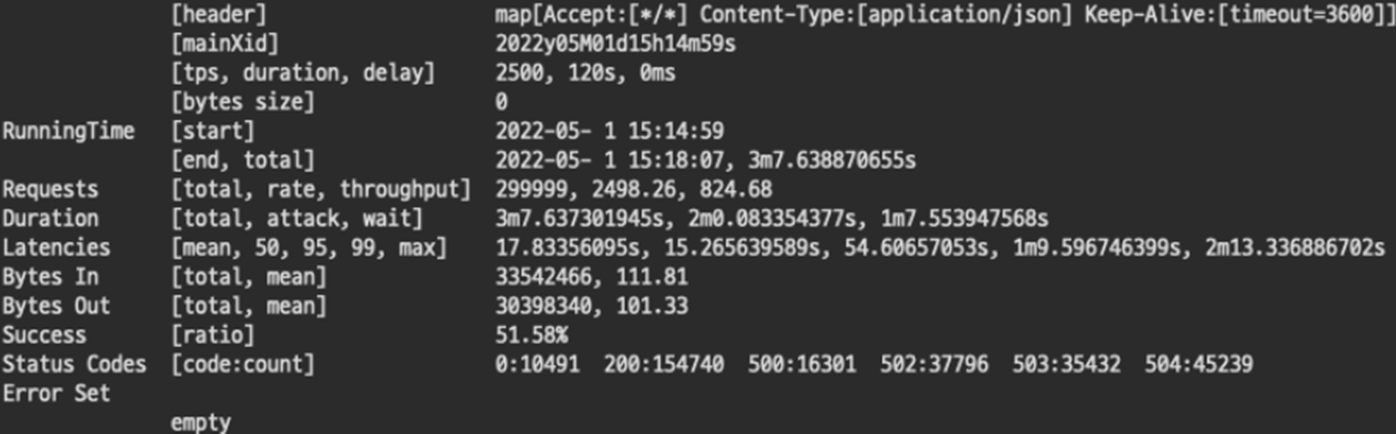

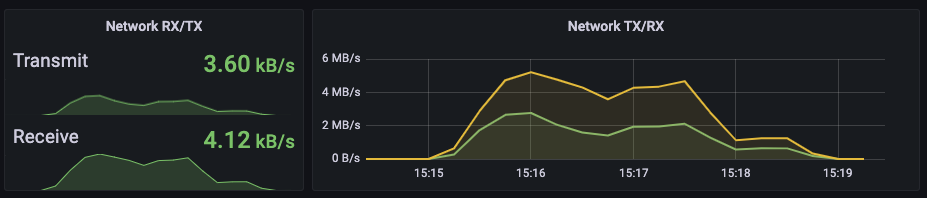
1500으로는 2500도 처리하지 못했다. 이로서 확실하게 리소스와 성능은 비례하지 않음을 알 수 있었다. 트랜잭션이 몰림에따라 애플리케이션 하나만의 문제가 아니라 여러가지 영향이 있음이 분명하다. 혹시 게이트웨이 성능자체가 2000TPS 이상을 버티지 못하는건 아닐까? 테스트를 계속했다.
4#. 2000 cpu 2000 Mi

4-1. TPS 3000 OK
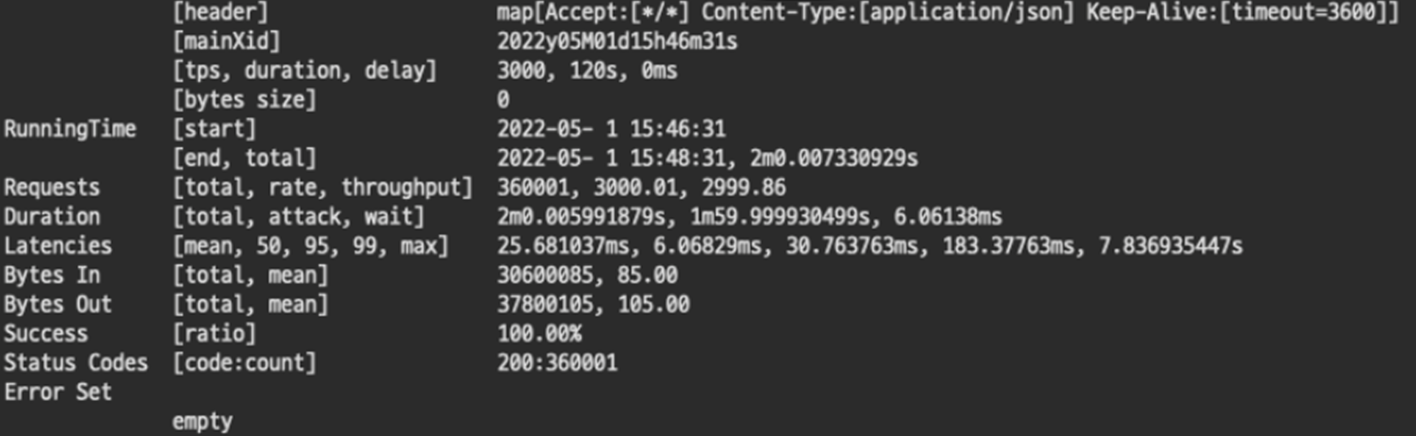
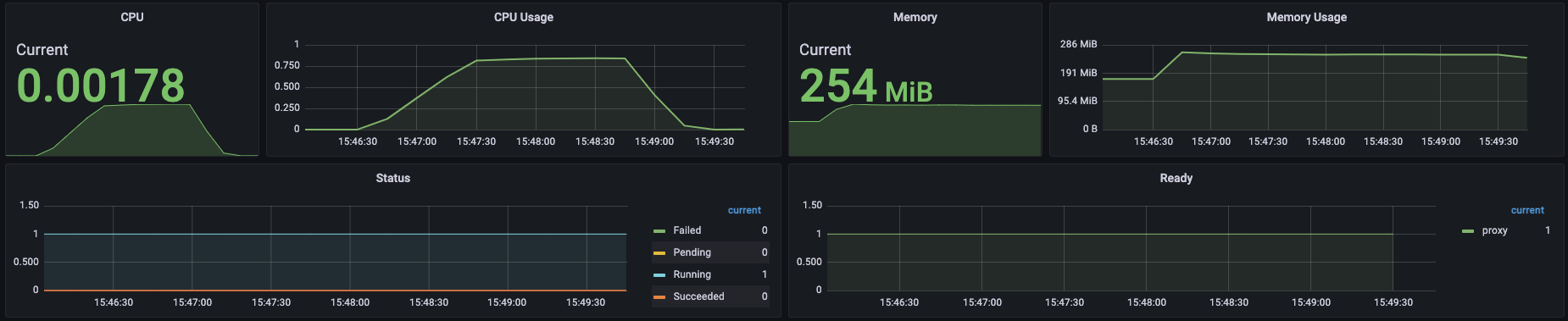
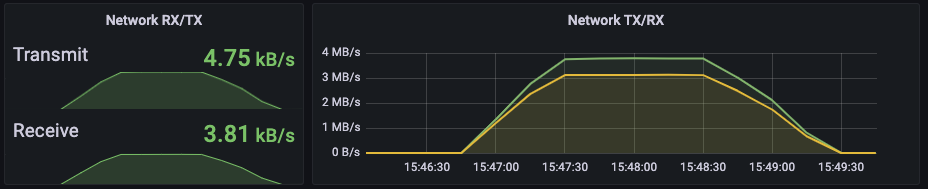
실패하지 않았다. 게이트웨이 자체의 문제는 아니었다. 리소스만 충분하다면 TPS가 높아져도 충분히 처리할 수 있다 보인다. 캡쳐를 하지 않았으나 소극적으로 TPS. 3500도 시도해봤는데 무난하게 성공했다. 처음 500리소스로 성공했던 1000의 4배인 TPS 4000이라면 어떨까?
4-2. TPS 4000 Fail
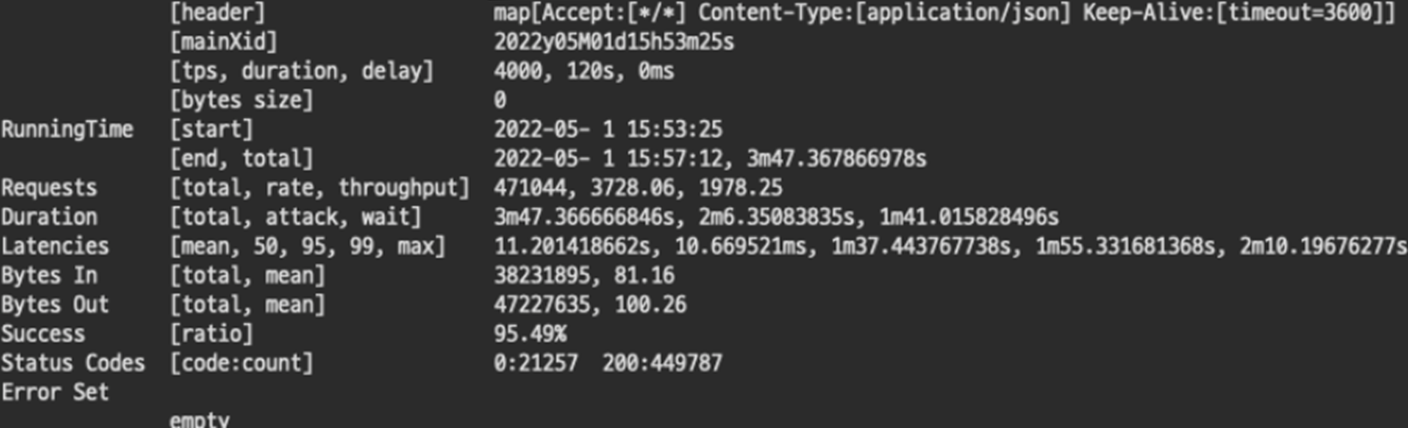
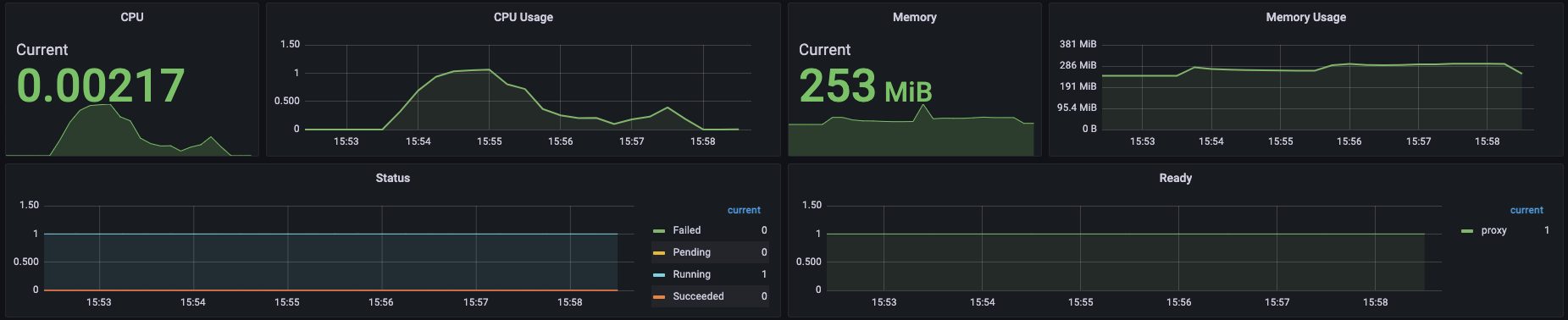
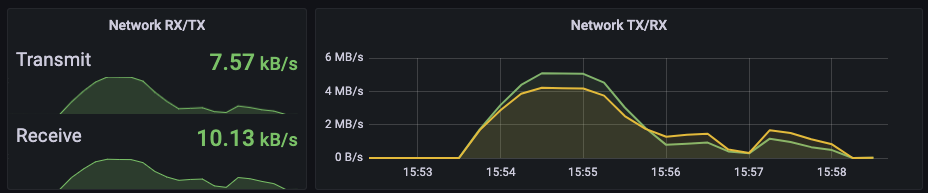
TPS 4000을 시도한 결과 실패했지만 아쉬운 수치를 보였다. 이후 3000 cpu, 3000 Mi로 동일한 TPS를 시도했으나 경우에 따라 95~100% 성공을 반복한 결과를 보였다. 또한, 4000 cpu, 4000 Mi로 TPS 4000 테스트 결과 항상 성공했으나 그래프가 이쁘게 보이지 않았다.
결론
이 테스트를 통해 '리소스에 따른 성능은 정비례하지 않는다'는 결론을 얻었다. 어쩌면 당연할지도 모르는 결과가 나와 아쉬웠지만 직접 눈으로 테스트 결과를 확인해볼 수 있었던 시도였다.
마무리
정리해보니 테스트가 상당히 단순하고 엉성하다고 생각된다. 인프라 지식이 부족하여 쿠버네티스, nginx 등 각종 외적인 부분에 대한 데이터를 제대로 확보하지 못했다. 계속 같은 환경에서 진행했기 때문에 테스트에 영향을 주지 않았을 거로 생각하지만 찜찜함은 남아있는 건 나중에 지식을 더 쌓아 극복해야겠다.
이번 부하 테스트를 통해 어느 정도 문제가 발생할 위험성이 떨어지고 가성비(?) 있는 구간이 2vCPU 2 GiB memory 라는 것을 직접 확인했으니 앞으로 가볍게 사용하는 수치로 기억해놔야겠다.
쿠버네티스를 사용한 리소스와 성능의 상관관계를 알아보았는데 다음에는 게이트웨이 없이 같은 클러스터 내에 두 개의 노드를 두고 AWS 인스턴스 타입을 바꿔가며 순수한 노드 리소스에 따른 성능을 비교해봐야겠다.


